


My first dive into the Twitter Files is coming soon
And the water is warm.

This week I went to San Francisco for my first peek at the “Twitter Files,” the company’s records on the government and private pressures it has faced to censor free speech and debate.
Since buying Twitter in late October, Elon Musk has opened the files to a handful of journalists. He invited me about 10 days ago to look over Covid-related documents at Twitter’s headquarters in no-longer-beautiful downtown San Francisco.
“Look over” is not entirely accurate, though. These files are not separate from Twitter’s other databases, they are part of them.
What Musk is really offering is the chance to search Twitter’s systems seeking information about specific topics, in a process akin to discovery in civil lawsuits. Reporters ask for searches. Twitter turns over what it finds to be read or screenshotted at Twitter headquarters but retains the original documents.
Beyond that, I agreed to no conditions on how I will use the information from the files. I can write what I like and do not have to preclear anything with Musk or anyone else. I will redact the names of low-level Twitter employees who were not in decision-making roles - I agreed to this condition in my lawsuit discovery too.
(Next stop, Twitter Files)

—
The mainstream media has downplayed or simply ignored Musk’s move, but it is hard to overstate how important it is - or how exceptional.
Big companies simply do not open their internal records for outsiders to pore over. Even in litigation, they place confidentiality protections on information they give to plaintiffs’ lawyers.
In contrast, Musk is making available an unprecedented trove of evidence about government and private efforts to suppress free speech on the most important global platform for journalism. Musk’s decision is not risk-free and has little or no appreciable benefit for him. Everyone - Democrat, Republican, or independent - should thank him for doing it.
—
(SIGN UP NOW TO HELP SEND ME BACK TO SAN FRANCISCO, WHICH LOOKS MORE LIKE BLADE RUNNER EVERY NIGHT)
—
The Twitter Files have already borne fruit.
The most important revelations so far came from Matt Taibbi’s reporting on the Twitter’s close relationship with the Federal Bureau of Investigation on so-called election misinformation.
The files leave little doubt that the FBI actively collaborated with Twitter to suppress Americans’ freedom of speech and push a fake narrative that Russia was successfully influencing American elections. The bureau went so far as to flag individual tweets for removal.
Yes, America’s most important federal law enforcement agency, a 35,000-employee force supposedly dedicated to stopping terrorism and serious crime, somehow decided that its job was to tell a social media company what content it could carry.
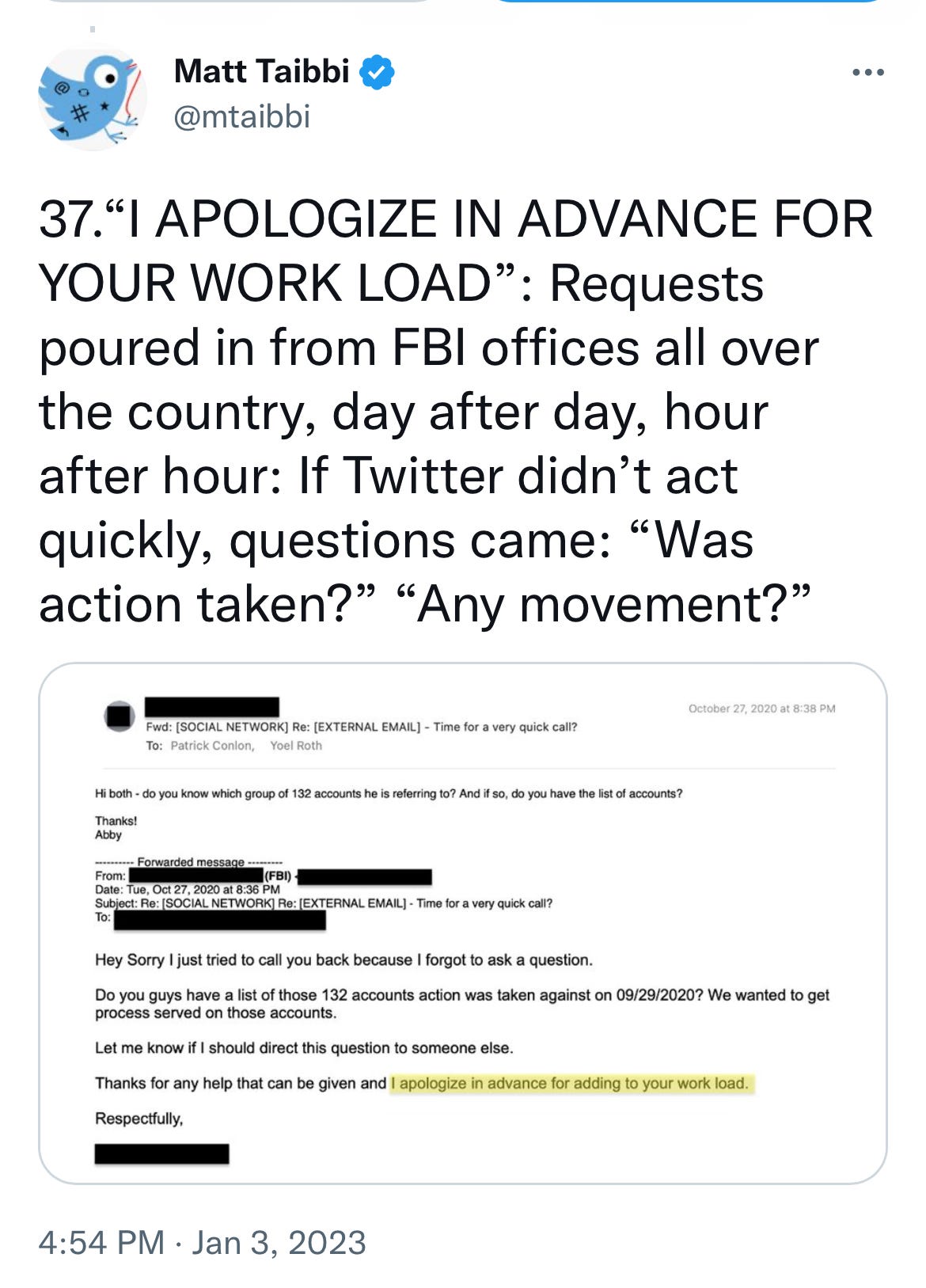
—
The files so far have not turned up much evidence of FBI interest in censoring discussion around the coronavirus or the Covid vaccines.
The Department of Homeland Security, the public health bureaucracies, and the Biden Administration itself seem to have led that effort, which accelerated dramatically in early 2021, after the vaccines became widely available and Biden took over.
But we have much more to learn, and doing so will take time. Twitter’s databases are huge. Searching them is complex. Employees used email, the Slack corporate messaging system, and an internal tracking system called Jira for more urgent discussions.
They also communicated with federal and state agencies through other, semi-secret channels, which were neither open or disclosed to the public. The FBI used one called Teleporter, while Twitter directed health agencies to something called the Partner Support Portal. There may have been others too, and it remains unclear how searchable those databases are. Employees also used text messages, phone, and Signal, of course. Those records are probably gone for good.
Still, the email, Slack, and Jira databases alone contain vast amounts of potentially important information. But the email and Slack databases are held offsite, and searchers must tailor their requests because of the volume of data they contain and the potential to reveal personal information.
(The civil litigation discovery process has similar limits, as I learned when I sued Old Twitter. Even a theoretically open-ended search must have reasonable terms and be confined to subjects who might reasonably have information. Judges will not approve endless rooting through corporate databases.)
But Jira is available at Twitter headquarters, and I was able to search it for some crucial terms last week.
Let’s just say what turned up is fascinating - and will make someone very unhappy that Elon opened these files. A couple of someones, but one someone in particular.
The story will be coming soon. (Ironically, I am waiting for Twitter to pull the “do not amplify” tag from my account before I post. This piece needs the widest distribution possible, and having Twitter itself suppress a story that I have gotten based on its files doesn’t make much sense.)
Tick, tick, tick…
I probably have never looked forward to reading something more in my entire life.
This is why I was sure they wouldn't allow Musk to buy Twitter.
Instead they forced him to buy it.
What an own-goal.